- 1 Arizona Trees
- 2 Learner classes with special methods
- 3 Resampling for comparing train subsets and sizes
- 4 Compute resampling results in a project
- 5 Initialize a new project grid table
- 6 Combine and save results in a project
- 7 Compute several resampling jobs
- 8 Test a project with smaller data and fewer resampling iterations
- 9 P-values for comparing Same/Other/All training
- 10 P-values for full versus down-sampled SOAK results
- 11 Score benchmark results
-- A --
AZtrees
AutoTunerTorch_epochs
-- L --
LearnerRegrCVGlmnetSave
LearnerClassifCVGlmnetSave
-- P --
proj_compute()
proj_grid()
proj_results()
proj_results_save()
proj_fread()
proj_submit()
proj_compute_mpi()
proj_compute_all()
proj_todo()
proj_test()
pvalue()
pvalue_downsample()
-- R --
ResamplingSameOtherSizesCV
-- S --
score()
1 Arizona Trees
Description
Classification data set with polygons (groups which should not be split in CV) and subsets (region3 or region4).
Usage
data("AZtrees")Format
A data frame with 5956 observations on the following 25 variables.
region3a character vector
region4a character vector
polygona numeric vector
ya character vector
ycoordlatitude
xcoordlongitude
SAMPLE_1a numeric vector
SAMPLE_2a numeric vector
SAMPLE_3a numeric vector
SAMPLE_4a numeric vector
SAMPLE_5a numeric vector
SAMPLE_6a numeric vector
SAMPLE_7a numeric vector
SAMPLE_8a numeric vector
SAMPLE_9a numeric vector
SAMPLE_10a numeric vector
SAMPLE_11a numeric vector
SAMPLE_12a numeric vector
SAMPLE_13a numeric vector
SAMPLE_14a numeric vector
SAMPLE_15a numeric vector
SAMPLE_16a numeric vector
SAMPLE_17a numeric vector
SAMPLE_18a numeric vector
SAMPLE_19a numeric vector
SAMPLE_20a numeric vector
SAMPLE_21a numeric vector
Source
Paul Nelson Arellano, paul.arellano@nau.edu
Examples
data.table::setDTthreads(1L)
data(AZtrees)
task.obj <- mlr3::TaskClassif$new("AZtrees3", AZtrees, target="y")
task.obj$col_roles$feature <- grep("SAMPLE", names(AZtrees), value=TRUE)
task.obj$col_roles$group <- "polygon"
task.obj$col_roles$subset <- "region3"
str(task.obj)
#> Classes 'TaskClassif', 'TaskSupervised', 'Task', 'R6' <TaskClassif:AZtrees3>
same_other_sizes_cv <- mlr3resampling::ResamplingSameOtherSizesCV$new()
same_other_sizes_cv$instantiate(task.obj)
same_other_sizes_cv$instance$iteration.dt
#> test.subset train.subsets groups test.fold
#> <char> <char> <int> <int>
#> 1: NE all 125 1
#> 2: NW all 125 1
#> 3: S all 125 1
#> 4: NE all 125 2
#> 5: NW all 125 2
#> 6: S all 125 2
#> 7: NE all 125 3
#> 8: NW all 125 3
#> 9: S all 125 3
#> 10: NE other 55 1
#> 11: NW other 104 1
#> 12: S other 91 1
#> 13: NE other 55 2
#> 14: NW other 104 2
#> 15: S other 91 2
#> 16: NE other 55 3
#> 17: NW other 104 3
#> 18: S other 91 3
#> 19: NE same 70 1
#> 20: NW same 21 1
#> 21: S same 34 1
#> 22: NE same 70 2
#> 23: NW same 21 2
#> 24: S same 34 2
#> 25: NE same 70 3
#> 26: NW same 21 3
#> 27: S same 34 3
#> test.subset train.subsets groups test.fold
#> <char> <char> <int> <int>
#> test
#> <list>
#> 1: 17,18,19,20,21,22,...[349]
#> 2: 1520,1521,1522,1523,1524,1525,...[60]
#> 3: 2904,2905,2906,2907,2908,2909,...[1577]
#> 4: 5, 6, 7, 8,11,12,...[865]
#> 5: 1918,1919,1920,1921,1922,1923,...[261]
#> 6: 2954,2955,2956,2957,2958,2959,...[859]
#> 7: 1, 2, 3, 4, 9,10,...[250]
#> 8: 773,774,775,776,777,778,...[1242]
#> 9: 2992,2993,2994,2995,2996,2997,...[493]
#> 10: 17,18,19,20,21,22,...[349]
#> 11: 1520,1521,1522,1523,1524,1525,...[60]
#> 12: 2904,2905,2906,2907,2908,2909,...[1577]
#> 13: 5, 6, 7, 8,11,12,...[865]
#> 14: 1918,1919,1920,1921,1922,1923,...[261]
#> 15: 2954,2955,2956,2957,2958,2959,...[859]
#> 16: 1, 2, 3, 4, 9,10,...[250]
#> 17: 773,774,775,776,777,778,...[1242]
#> 18: 2992,2993,2994,2995,2996,2997,...[493]
#> 19: 17,18,19,20,21,22,...[349]
#> 20: 1520,1521,1522,1523,1524,1525,...[60]
#> 21: 2904,2905,2906,2907,2908,2909,...[1577]
#> 22: 5, 6, 7, 8,11,12,...[865]
#> 23: 1918,1919,1920,1921,1922,1923,...[261]
#> 24: 2954,2955,2956,2957,2958,2959,...[859]
#> 25: 1, 2, 3, 4, 9,10,...[250]
#> 26: 773,774,775,776,777,778,...[1242]
#> 27: 2992,2993,2994,2995,2996,2997,...[493]
#> test
#> <list>
#> train seed n.train.groups iteration
#> <list> <int> <int> <int>
#> 1: 1,2,3,4,5,6,...[3970] 1 125 1
#> 2: 1,2,3,4,5,6,...[3970] 1 125 2
#> 3: 1,2,3,4,5,6,...[3970] 1 125 3
#> 4: 1, 2, 3, 4, 9,10,...[3971] 1 125 4
#> 5: 1, 2, 3, 4, 9,10,...[3971] 1 125 5
#> 6: 1, 2, 3, 4, 9,10,...[3971] 1 125 6
#> 7: 5, 6, 7, 8,11,12,...[3971] 1 125 7
#> 8: 5, 6, 7, 8,11,12,...[3971] 1 125 8
#> 9: 5, 6, 7, 8,11,12,...[3971] 1 125 9
#> 10: 773,774,775,776,777,778,...[2855] 1 55 10
#> 11: 1,2,3,4,5,6,...[2467] 1 104 11
#> 12: 1,2,3,4,5,6,...[2618] 1 91 12
#> 13: 773,774,775,776,777,778,...[3372] 1 55 13
#> 14: 1, 2, 3, 4, 9,10,...[2669] 1 104 14
#> 15: 1, 2, 3, 4, 9,10,...[1901] 1 91 15
#> 16: 1520,1521,1522,1523,1524,1525,...[2757] 1 55 16
#> 17: 5, 6, 7, 8,11,12,...[3650] 1 104 17
#> 18: 5, 6, 7, 8,11,12,...[1535] 1 91 18
#> 19: 1,2,3,4,5,6,...[1115] 1 70 19
#> 20: 773,774,775,776,777,778,...[1503] 1 21 20
#> 21: 2954,2955,2956,2957,2958,2959,...[1352] 1 34 21
#> 22: 1, 2, 3, 4, 9,10,...[599] 1 70 22
#> 23: 773,774,775,776,777,778,...[1302] 1 21 23
#> 24: 2904,2905,2906,2907,2908,2909,...[2070] 1 34 24
#> 25: 5, 6, 7, 8,11,12,...[1214] 1 70 25
#> 26: 1520,1521,1522,1523,1524,1525,...[321] 1 21 26
#> 27: 2904,2905,2906,2907,2908,2909,...[2436] 1 34 27
#> train seed n.train.groups iteration
#> <list> <int> <int> <int>
#> Train_subsets
#> <fctr>
#> 1: all
#> 2: all
#> 3: all
#> 4: all
#> 5: all
#> 6: all
#> 7: all
#> 8: all
#> 9: all
#> 10: other
#> 11: other
#> 12: other
#> 13: other
#> 14: other
#> 15: other
#> 16: other
#> 17: other
#> 18: other
#> 19: same
#> 20: same
#> 21: same
#> 22: same
#> 23: same
#> 24: same
#> 25: same
#> 26: same
#> 27: same
#> Train_subsets
#> <fctr>
2 Learner classes with special methods
Description
AutoTunerTorch_epochs inherits from
mlr3tuning::AutoTuner, with an initialize method that
takes arguments to construct a torch module learner. It runs gradient
descent up to max_epochs and then re-runs using the best number
of epochs. Its edit_learner method sets number of epochs to 2
(for quick learning during proj_test),
and its save_learner method returns a history data table (one
row per epoch).
LearnerRegrCVGlmnetSave inherits from
LearnerRegrCVGlmnet; its save_learner method returns a
data table of regularized linear model weights (no edit_learner
method).
LearnerClassifCVGlmnetSave is similar.
Author(s)
Toby Dylan Hocking
Examples
## Simulate regression data.
N <- 80
library(data.table)
set.seed(1)
reg.dt <- data.table(
x=runif(N, -2, 2),
noise=runif(N, -2, 2),
person=factor(rep(c("Alice","Bob"), each=0.5*N)))
reg.pattern.list <- list(
easy=function(x, person)x^3,
impossible=function(x, person)(x^2)*(-1)^as.integer(person))
SOAK <- mlr3resampling::ResamplingSameOtherSizesCV$new()
reg.task.list <- list()
for(pattern in names(reg.pattern.list)){
f <- reg.pattern.list[[pattern]]
task.dt <- data.table(reg.dt)[
, y := f(x,person)+rnorm(N, sd=0.5)
][]
task.obj <- mlr3::TaskRegr$new(
pattern, task.dt, target="y")
task.obj$col_roles$feature <- c("x","noise")
task.obj$col_roles$stratum <- "person"
task.obj$col_roles$subset <- "person"
reg.task.list[[pattern]] <- task.obj
}
reg.task.list # two regression tasks.
#> $easy
#>
#> ── <TaskRegr> (80x3) ───────────────────────────────────────────────────────────
#> • Target: y
#> • Properties: strata
#> • Features (2):
#> • dbl (2): noise, x
#> • Strata: person
#>
#> $impossible
#>
#> ── <TaskRegr> (80x3) ───────────────────────────────────────────────────────────
#> • Target: y
#> • Properties: strata
#> • Features (2):
#> • dbl (2): noise, x
#> • Strata: person
## Create a list of learners.
reg.learner.list <- list(
featureless=mlr3::LearnerRegrFeatureless$new())
if(requireNamespace("mlr3torch") && torch::torch_is_installed()){
gen_linear <- torch::nn_module(
"my_linear",
initialize = function(task) {
self$weight = torch::nn_linear(task$n_features, 1)
},
forward = function(x) {
self$weight(x)
}
)
reg.learner.list$torch_linear <- mlr3resampling::AutoTunerTorch_epochs$new(
"torch_linear",
module_generator=gen_linear,
max_epochs=3,
batch_size=10,
loss=mlr3torch::t_loss("mse"),
measure_list=mlr3::msrs(c("regr.mse","regr.mae")))
}
if(requireNamespace("mlr3learners")){
reg.learner.list$cv_glmnet <- mlr3resampling::LearnerRegrCVGlmnetSave$new()
reg.learner.list$cv_glmnet$param_set$values$nfolds <- 3
}
reg.learner.list # a list of learners.
#> $featureless
#>
#> ── <LearnerRegrFeatureless> (regr.featureless): Featureless Regression Learner ─
#> • Model: -
#> • Parameters: robust=FALSE
#> • Packages: mlr3 and stats
#> • Predict Types: [response], se, and quantiles
#> • Feature Types: logical, integer, numeric, character, factor, ordered,
#> POSIXct, and Date
#> • Encapsulation: none (fallback: -)
#> • Properties: featureless, importance, missings, selected_features, and weights
#> • Other settings: use_weights = 'use', predict_raw = 'FALSE'
#>
#> $torch_linear
#>
#> ── <AutoTunerTorch_epochs> (torch_linear) ──────────────────────────────────────
#> • Model: -
#> • Parameters: list()
#> • Packages: mlr3, mlr3tuning, mlr3torch, and torch
#> • Predict Types: [response]
#> • Feature Types: logical, integer, numeric, character, factor, ordered,
#> POSIXct, Date, and lazy_tensor
#> • Encapsulation: none (fallback: -)
#> • Properties: featureless, hotstart_backward, hotstart_forward, importance,
#> marshal, missings, new_levels, offset, oob_error, selected_features, and
#> weights
#> • Other settings: use_weights = 'use', predict_raw = 'FALSE'
#> • Search Space:
#> id class lower upper nlevels
#> <char> <char> <num> <num> <num>
#> 1: epochs ParamInt 0 3 4
#>
#> $cv_glmnet
#>
#> ── <LearnerRegrCVGlmnetSave> (regr.cv_glmnet): GLM with Elastic Net Regularizati
#> • Model: -
#> • Parameters: nfolds=3, family=gaussian, use_pred_offset=TRUE, seed=NA
#> • Packages: mlr3, mlr3learners, and glmnet
#> • Predict Types: [response]
#> • Feature Types: logical, integer, and numeric
#> • Encapsulation: none (fallback: -)
#> • Properties: offset, selected_features, and weights
#> • Other settings: use_weights = 'use', predict_raw = 'FALSE'
# 2-fold CV.
kfold <- mlr3::ResamplingCV$new()
kfold$param_set$values$folds <- 2
# Create project grid.
pkg.proj.dir <- tempfile()
pgrid <- mlr3resampling::proj_grid(
pkg.proj.dir,
reg.task.list,
reg.learner.list,
score_args=mlr3::msrs("regr.rmse"),
kfold)
test_out <- mlr3resampling::proj_test(pkg.proj.dir)
test_out$learners_history.csv # from AutoTunerTorch_epochs, 2 epochs for testing.
test_out$learners_weights.csv # from LearnerRegrCVGlmnetSave
torch.job.i <- which(pgrid$learner_id=="torch_linear")[1]
mlr3resampling::proj_compute(torch.job.i, pkg.proj.dir)
mlr3resampling::proj_results_save(pkg.proj.dir)
full_out <- mlr3resampling::proj_fread(pkg.proj.dir)
full_out$learners_history.csv # from AutoTunerTorch_epochs, 3 epochs.
3 Resampling for comparing train subsets and sizes
Description
ResamplingSameOtherSizesCV
defines how a task is partitioned for
resampling, for example in
resample() or
benchmark().
Resampling objects can be instantiated on a
Task,
which can use two new roles: subset and fold.
After instantiation, sets can be accessed via
$train_set(i) and
$test_set(i), respectively.
Details
This is an implementation of SOAK, Same/Other/All K-fold cross-validation. A supervised learning algorithm inputs a train set, and outputs a prediction function, which can be used on a test set. If each data point belongs to a subset (such as geographic region, year, etc), then how do we know if it is possible to train on one subset, and predict accurately on another subset? Cross-validation can be used to determine the extent to which this is possible, by first assigning fold IDs from 1 to K to all data (possibly using stratification, usually by subset and label). Then we loop over test sets (subset/fold combinations), train sets (same subset, other subsets, all subsets), and compute test/prediction accuracy for each combination. Comparing test/prediction accuracy between same and other, we can determine the extent to which it is possible (perfect if same/other have similar test accuracy for each subset; other is usually somewhat less accurate than same; other can be just as bad as featureless baseline when the subsets have different patterns).
Stratification
ResamplingSameOtherSizesCV supports stratified sampling.
The stratification variables are assumed to be discrete,
and must be stored in the Task with column role
stratum.
If that role is not set, then all data are assigned to one stratum.
In case of multiple stratification variables,
each combination of the values of the stratification variables forms a
stratum.
When fold role is set, stratum role is not used for fold
assignment (folds are taken from fold role in that case).
When sizes param is at least 0, then downsampled train sets are
created, and if stratum role is set, we attempt to preserve
strata proportions in downsampled train sets.
Grouping
ResamplingSameOtherSizesCV supports grouping of
observations that will not be split in cross-validation.
The grouping variable is assumed to be discrete,
and must be stored in the Task with column role
group.
If that role is not set, then each row is assigned to a different group.
When fold role is set, group role is not used for fold
assignment (folds are taken from fold role in that case).
When sizes param is at least 0, then downsampled train sets are
created, and if group role is set, we keep groups together
in downsampled train sets.
Subsets
ResamplingSameOtherSizesCV supports fixing a test subset,
then training on same/other/all subsets.
The subset variable is assumed to be discrete,
and must be stored in the Task with column role subset.
Parameters
The number of cross-validation folds K should be defined as the
fold parameter, default 3.
The number of random seeds for downsampling should be defined as the
seeds parameter, default 1.
The number of downsampling train set sizes should be defined as
the sizes parameter, which can also take two special values:
default -1 means no downsampling at all, and 0 means only downsampling
to the min of same/other sets (in units of groups).
The ratio for downsampling should be defined as the ratio
parameter, default 0.5. The min size of same and other sets is
repeatedly multiplied by this ratio, to obtain smaller sizes (in units
of groups).
The ignore_subset parameter should be either TRUE or
FALSE (default), whether to ignore the subset
role. TRUE only creates splits for same subset (even if task
defines subset role), and is useful for subtrain/validation
splits (hyper-parameter learning).
The subsets parameter should specify the train subsets of
interest: "S" (same),
"O" (other), "A" (all), "SO", "SA",
"SOA" (default).
If fold column role is set, then that column will be used for
non-random fold assignment (see Reproducibility vignette).
Otherwise, the group_stratum_algo parameter controls the algorithm used for
random fold assignment.
We want to assign folds such that groups are not split (hard
constraint), and strata proportions are preserved (objective to
optimize).
To see exemples of how this works,
read the vignette, Using subset with group and stratum.
Note that this feature works on tasks with both stratum and
group roles (unlike ResamplingCV).
Computing an optimal fold assignment is NP-hard (discrete, need
to try all possible assignments of groups to folds to find best
solution).
Instead of computing the optimal solution (slow), we implement heuristic
algorithms (fast), which yield approximate solutions.
The choice of which heuristic is controlled by the
group_stratum_algo parameter, which can take these values:
"RSS"Default, novel heuristic algorithm which attempts to minimize the residual sum of squares, between actual and ideal values of the strata/fold count matrix. First groups are sorted by RSS (group counts - ideal counts per stratum); ties are broken using number of samples in group, mean(ideal*actual) counts (mean over strata), random group order. Then each group is greedily assigned a fold in order; best fold results in min RSS, ties broken using total counts above ideal. For N data, K folds, G groups, and S strata, the algorithm is
O(N + K G S)time andO(N + S K)memory."Wasikowski"Same heuristic algorithm as in scikit-learn
StratifiedGroupKFold, adapted from https://www.kaggle.com/code/jakubwasikowski/stratified-group-k-fold-cross-validation. First groups are sorted by standard deviation over strata counts; ties are broken by random group order. Then each group is greedily assigned a fold in order; best fold results in the smallest mean SD of the strata/fold count matrix (SD over folds is computed for each stratum, then mean of SDs, minimized over folds), ties broken using number of samples in fold. For N data, K folds, G groups, and S strata, the algorithm isO(N + K^2 G S)time andO(N + S K + S G)memory (could be problematic when G and S are both large)."WasikowskiLimitedMemory"Same logic and time complexity but only
O(N + S K)memory.
The train/test splits are defined by all possible combinations of
test subset, test fold, train subsets (same/other/all), downsampling
sizes, and random seeds.
After $instantiate() is called,
$instance is a list of data about the splits, with elements:
- iteration.dt
data table with one row per split.
- fold.dt
data table with same number of rows as task data.
Methods
Public methods
Method new()
Creates a new instance of this R6 class.
Usage
Resampling$new( id, param_set = ps(), duplicated_ids = FALSE, label = NA_character_, man = NA_character_ )
Arguments
id(
character(1))
Identifier for the new instance.param_set(paradox::ParamSet)
Set of hyperparameters.duplicated_ids(
logical(1))
Set toTRUEif this resampling strategy may have duplicated row ids in a single training set or test set.label(
character(1))
Label for the new instance.man(
character(1))
String in the format[pkg]::[topic]pointing to a manual page for this object. The referenced help package can be opened via method$help().
Method train_set()
Returns the row ids of the i-th training set.
Usage
Resampling$train_set(i)
Arguments
i(
integer(1))
Iteration.
Returns
(integer()) of row ids.
Method test_set()
Returns the row ids of the i-th test set.
Usage
Resampling$test_set(i)
Arguments
i(
integer(1))
Iteration.
Returns
(integer()) of row ids.
See Also
arXiv paper https://arxiv.org/abs/2410.08643 describing SOAK algorithm.
Articles https://github.com/tdhock/mlr3resampling/wiki/Articles
Package mlr3 for standard
Resampling, which does not support comparing train on Same/Other/All subsets.-
vignette(package="mlr3resampling")for more detailed examples.
Examples
same_other_sizes <- mlr3resampling::ResamplingSameOtherSizesCV$new()
same_other_sizes$param_set$values$folds <- 5
4 Compute resampling results in a project
Description
Runs train() and predict(), then a data table
with one row is saved to an RDS file in the grid_jobs
directory.
Usage
proj_compute(grid_job_i, proj_dir, verbose=FALSE, process_fun=Sys.getpid)Arguments
grid_job_i |
integer from 1 to number of jobs (rows in |
proj_dir |
Project directory created by |
verbose |
Logical: print messages? |
process_fun |
function called with no arguments
(default |
Details
If everything goes well, the user should not need to run this
function.
Instead, the user runs proj_submit as Step 2 out of the
typical 3 step pipeline (init grid, submit, read results).
proj_compute can sometimes be useful for testing or debugging the submit step,
since it runs one split at a time.
Value
proj_compute returns a data table with one row of results.
Author(s)
Toby Dylan Hocking
Examples
N <- 80
library(data.table)
set.seed(1)
reg.dt <- data.table(
x=runif(N, -2, 2),
person=factor(rep(c("Alice","Bob"), each=0.5*N)))
reg.pattern.list <- list(
easy=function(x, person)x^2,
impossible=function(x, person)(x^2)*(-1)^as.integer(person))
SOAK <- mlr3resampling::ResamplingSameOtherSizesCV$new()
reg.task.list <- list()
for(pattern in names(reg.pattern.list)){
f <- reg.pattern.list[[pattern]]
task.dt <- data.table(reg.dt)[
, y := f(x,person)+rnorm(N, sd=0.5)
][]
task.obj <- mlr3::TaskRegr$new(
pattern, task.dt, target="y")
task.obj$col_roles$feature <- "x"
task.obj$col_roles$stratum <- "person"
task.obj$col_roles$subset <- "person"
reg.task.list[[pattern]] <- task.obj
}
reg.learner.list <- list(
featureless=mlr3::LearnerRegrFeatureless$new())
if(requireNamespace("rpart")){
reg.learner.list$rpart <- mlr3::LearnerRegrRpart$new()
}
pkg.proj.dir <- tempfile()
mlr3resampling::proj_grid(
pkg.proj.dir,
reg.task.list,
reg.learner.list,
SOAK,
order_jobs = function(DT)1:2, # for CRAN.
score_args=mlr3::msrs(c("regr.rmse", "regr.mae")))
#> task.i learner.i resampling.i task_id learner_id resampling_id
#> <int> <int> <int> <char> <char> <char>
#> 1: 1 1 1 easy regr.featureless same_other_sizes_cv
#> 2: 1 1 1 easy regr.featureless same_other_sizes_cv
#> test.subset train.subsets groups test.fold seed n.train.groups iteration
#> <fctr> <char> <int> <int> <int> <int> <int>
#> 1: Alice all 52 1 1 52 1
#> 2: Bob all 52 1 1 52 2
#> Train_subsets
#> <fctr>
#> 1: all
#> 2: all
mlr3resampling::proj_compute(1, pkg.proj.dir)
#> task.i learner.i resampling.i task_id learner_id resampling_id
#> <int> <int> <int> <char> <char> <char>
#> 1: 1 1 1 easy regr.featureless same_other_sizes_cv
#> test.subset train.subsets groups test.fold seed n.train.groups iteration
#> <char> <char> <int> <int> <int> <int> <int>
#> 1: Alice all 52 1 1 52 1
#> Train_subsets start.time end.time process learner pred
#> <char> <POSc> <POSc> <int> <list> <list>
#> 1: all 2026-06-27 03:55:27 2026-06-27 03:55:27 9868 [NULL] [NULL]
#> regr.rmse regr.mae
#> <num> <num>
#> 1: 1.165174 0.8521147
5 Initialize a new project grid table
Description
A project grid consists of all combinations of tasks, learners, resampling types, and resampling iterations, to be computed in parallel. This function creates a project directory with files to describe the grid.
Usage
proj_grid(
proj_dir, tasks, learners, resamplings,
order_jobs = NULL, score_args = NULL,
save_learner = save_learner_default, save_pred = FALSE,
train_seed = 1L, resampling_seed = 1L)Arguments
proj_dir |
Path to directory to create. |
tasks |
List of Tasks, or a single Task. |
learners |
List of Learners, or a single Learner. |
resamplings |
List of Resamplings, or a single Resampling. |
order_jobs |
Function which takes split table as input, and
returns integer vector of row numbers of the split table to write to
|
score_args |
Passed to |
save_learner |
Function to process Learner, after
training/prediction, but before saving result to disk.
For interpreting complex models, you should write a function that
returns only the parts of the model that you need (and discards the
other parts which would take up disk space for no reason).
Default is to call |
save_pred |
Function to process Prediction before saving to disk.
Default |
train_seed |
integer: random seed to set before training (default
|
resampling_seed |
integer: random seed to set before
instantiating each resampling (default |
Details
This is Step 1 out of the
typical 3 step pipeline (init grid, submit, read results).
It creates a grid_jobs.csv table which has a column status;
each row is initialized to "not started" or "done",
depending on whether the corresponding result RDS file exists already.
Value
Data table of splits to be processed (same as table saved to grid_jobs.rds).
Author(s)
Toby Dylan Hocking
Examples
N <- 80
library(data.table)
set.seed(1)
reg.dt <- data.table(
x=runif(N, -2, 2),
person=factor(rep(c("Alice","Bob"), each=0.5*N)))
reg.pattern.list <- list(
easy=function(x, person)x^2,
impossible=function(x, person)(x^2)*(-1)^as.integer(person))
SOAK <- mlr3resampling::ResamplingSameOtherSizesCV$new()
reg.task.list <- list()
for(pattern in names(reg.pattern.list)){
f <- reg.pattern.list[[pattern]]
task.dt <- data.table(reg.dt)[
, y := f(x,person)+rnorm(N, sd=0.5)
][]
task.obj <- mlr3::TaskRegr$new(
pattern, task.dt, target="y")
task.obj$col_roles$feature <- "x"
task.obj$col_roles$stratum <- "person"
task.obj$col_roles$subset <- "person"
reg.task.list[[pattern]] <- task.obj
}
reg.learner.list <- list(
featureless=mlr3::LearnerRegrFeatureless$new())
if(requireNamespace("rpart")){
reg.learner.list$rpart <- mlr3::LearnerRegrRpart$new()
}
pkg.proj.dir <- tempfile()
mlr3resampling::proj_grid(
pkg.proj.dir,
reg.task.list,
reg.learner.list,
SOAK,
score_args=mlr3::msrs(c("regr.rmse", "regr.mae")))
#> task.i learner.i resampling.i task_id learner_id
#> <int> <int> <int> <char> <char>
#> 1: 1 1 1 easy regr.featureless
#> 2: 1 1 1 easy regr.featureless
#> 3: 1 1 1 easy regr.featureless
#> 4: 1 1 1 easy regr.featureless
#> 5: 1 1 1 easy regr.featureless
#> 6: 1 1 1 easy regr.featureless
#> 7: 1 2 1 easy regr.rpart
#> 8: 1 2 1 easy regr.rpart
#> 9: 1 2 1 easy regr.rpart
#> 10: 1 2 1 easy regr.rpart
#> 11: 1 2 1 easy regr.rpart
#> 12: 1 2 1 easy regr.rpart
#> 13: 2 1 1 impossible regr.featureless
#> 14: 2 1 1 impossible regr.featureless
#> 15: 2 1 1 impossible regr.featureless
#> 16: 2 1 1 impossible regr.featureless
#> 17: 2 1 1 impossible regr.featureless
#> 18: 2 1 1 impossible regr.featureless
#> 19: 2 2 1 impossible regr.rpart
#> 20: 2 2 1 impossible regr.rpart
#> 21: 2 2 1 impossible regr.rpart
#> 22: 2 2 1 impossible regr.rpart
#> 23: 2 2 1 impossible regr.rpart
#> 24: 2 2 1 impossible regr.rpart
#> 25: 1 1 1 easy regr.featureless
#> 26: 1 1 1 easy regr.featureless
#> 27: 1 1 1 easy regr.featureless
#> 28: 1 1 1 easy regr.featureless
#> 29: 1 1 1 easy regr.featureless
#> 30: 1 1 1 easy regr.featureless
#> 31: 1 1 1 easy regr.featureless
#> 32: 1 1 1 easy regr.featureless
#> 33: 1 1 1 easy regr.featureless
#> 34: 1 1 1 easy regr.featureless
#> 35: 1 1 1 easy regr.featureless
#> 36: 1 1 1 easy regr.featureless
#> 37: 1 2 1 easy regr.rpart
#> 38: 1 2 1 easy regr.rpart
#> 39: 1 2 1 easy regr.rpart
#> 40: 1 2 1 easy regr.rpart
#> 41: 1 2 1 easy regr.rpart
#> 42: 1 2 1 easy regr.rpart
#> 43: 1 2 1 easy regr.rpart
#> 44: 1 2 1 easy regr.rpart
#> 45: 1 2 1 easy regr.rpart
#> 46: 1 2 1 easy regr.rpart
#> 47: 1 2 1 easy regr.rpart
#> 48: 1 2 1 easy regr.rpart
#> 49: 2 1 1 impossible regr.featureless
#> 50: 2 1 1 impossible regr.featureless
#> 51: 2 1 1 impossible regr.featureless
#> 52: 2 1 1 impossible regr.featureless
#> 53: 2 1 1 impossible regr.featureless
#> 54: 2 1 1 impossible regr.featureless
#> 55: 2 1 1 impossible regr.featureless
#> 56: 2 1 1 impossible regr.featureless
#> 57: 2 1 1 impossible regr.featureless
#> 58: 2 1 1 impossible regr.featureless
#> 59: 2 1 1 impossible regr.featureless
#> 60: 2 1 1 impossible regr.featureless
#> 61: 2 2 1 impossible regr.rpart
#> 62: 2 2 1 impossible regr.rpart
#> 63: 2 2 1 impossible regr.rpart
#> 64: 2 2 1 impossible regr.rpart
#> 65: 2 2 1 impossible regr.rpart
#> 66: 2 2 1 impossible regr.rpart
#> 67: 2 2 1 impossible regr.rpart
#> 68: 2 2 1 impossible regr.rpart
#> 69: 2 2 1 impossible regr.rpart
#> 70: 2 2 1 impossible regr.rpart
#> 71: 2 2 1 impossible regr.rpart
#> 72: 2 2 1 impossible regr.rpart
#> task.i learner.i resampling.i task_id learner_id
#> <int> <int> <int> <char> <char>
#> resampling_id test.subset train.subsets groups test.fold seed
#> <char> <fctr> <char> <int> <int> <int>
#> 1: same_other_sizes_cv Alice all 52 1 1
#> 2: same_other_sizes_cv Bob all 52 1 1
#> 3: same_other_sizes_cv Alice all 52 2 1
#> 4: same_other_sizes_cv Bob all 52 2 1
#> 5: same_other_sizes_cv Alice all 52 3 1
#> 6: same_other_sizes_cv Bob all 52 3 1
#> 7: same_other_sizes_cv Alice all 52 1 1
#> 8: same_other_sizes_cv Bob all 52 1 1
#> 9: same_other_sizes_cv Alice all 52 2 1
#> 10: same_other_sizes_cv Bob all 52 2 1
#> 11: same_other_sizes_cv Alice all 52 3 1
#> 12: same_other_sizes_cv Bob all 52 3 1
#> 13: same_other_sizes_cv Alice all 52 1 1
#> 14: same_other_sizes_cv Bob all 52 1 1
#> 15: same_other_sizes_cv Alice all 52 2 1
#> 16: same_other_sizes_cv Bob all 52 2 1
#> 17: same_other_sizes_cv Alice all 52 3 1
#> 18: same_other_sizes_cv Bob all 52 3 1
#> 19: same_other_sizes_cv Alice all 52 1 1
#> 20: same_other_sizes_cv Bob all 52 1 1
#> 21: same_other_sizes_cv Alice all 52 2 1
#> 22: same_other_sizes_cv Bob all 52 2 1
#> 23: same_other_sizes_cv Alice all 52 3 1
#> 24: same_other_sizes_cv Bob all 52 3 1
#> 25: same_other_sizes_cv Alice other 26 1 1
#> 26: same_other_sizes_cv Bob other 26 1 1
#> 27: same_other_sizes_cv Alice other 26 2 1
#> 28: same_other_sizes_cv Bob other 26 2 1
#> 29: same_other_sizes_cv Alice other 26 3 1
#> 30: same_other_sizes_cv Bob other 26 3 1
#> 31: same_other_sizes_cv Alice same 26 1 1
#> 32: same_other_sizes_cv Bob same 26 1 1
#> 33: same_other_sizes_cv Alice same 26 2 1
#> 34: same_other_sizes_cv Bob same 26 2 1
#> 35: same_other_sizes_cv Alice same 26 3 1
#> 36: same_other_sizes_cv Bob same 26 3 1
#> 37: same_other_sizes_cv Alice other 26 1 1
#> 38: same_other_sizes_cv Bob other 26 1 1
#> 39: same_other_sizes_cv Alice other 26 2 1
#> 40: same_other_sizes_cv Bob other 26 2 1
#> 41: same_other_sizes_cv Alice other 26 3 1
#> 42: same_other_sizes_cv Bob other 26 3 1
#> 43: same_other_sizes_cv Alice same 26 1 1
#> 44: same_other_sizes_cv Bob same 26 1 1
#> 45: same_other_sizes_cv Alice same 26 2 1
#> 46: same_other_sizes_cv Bob same 26 2 1
#> 47: same_other_sizes_cv Alice same 26 3 1
#> 48: same_other_sizes_cv Bob same 26 3 1
#> 49: same_other_sizes_cv Alice other 26 1 1
#> 50: same_other_sizes_cv Bob other 26 1 1
#> 51: same_other_sizes_cv Alice other 26 2 1
#> 52: same_other_sizes_cv Bob other 26 2 1
#> 53: same_other_sizes_cv Alice other 26 3 1
#> 54: same_other_sizes_cv Bob other 26 3 1
#> 55: same_other_sizes_cv Alice same 26 1 1
#> 56: same_other_sizes_cv Bob same 26 1 1
#> 57: same_other_sizes_cv Alice same 26 2 1
#> 58: same_other_sizes_cv Bob same 26 2 1
#> 59: same_other_sizes_cv Alice same 26 3 1
#> 60: same_other_sizes_cv Bob same 26 3 1
#> 61: same_other_sizes_cv Alice other 26 1 1
#> 62: same_other_sizes_cv Bob other 26 1 1
#> 63: same_other_sizes_cv Alice other 26 2 1
#> 64: same_other_sizes_cv Bob other 26 2 1
#> 65: same_other_sizes_cv Alice other 26 3 1
#> 66: same_other_sizes_cv Bob other 26 3 1
#> 67: same_other_sizes_cv Alice same 26 1 1
#> 68: same_other_sizes_cv Bob same 26 1 1
#> 69: same_other_sizes_cv Alice same 26 2 1
#> 70: same_other_sizes_cv Bob same 26 2 1
#> 71: same_other_sizes_cv Alice same 26 3 1
#> 72: same_other_sizes_cv Bob same 26 3 1
#> resampling_id test.subset train.subsets groups test.fold seed
#> <char> <fctr> <char> <int> <int> <int>
#> n.train.groups iteration Train_subsets
#> <int> <int> <fctr>
#> 1: 52 1 all
#> 2: 52 2 all
#> 3: 52 3 all
#> 4: 52 4 all
#> 5: 52 5 all
#> 6: 52 6 all
#> 7: 52 1 all
#> 8: 52 2 all
#> 9: 52 3 all
#> 10: 52 4 all
#> 11: 52 5 all
#> 12: 52 6 all
#> 13: 52 1 all
#> 14: 52 2 all
#> 15: 52 3 all
#> 16: 52 4 all
#> 17: 52 5 all
#> 18: 52 6 all
#> 19: 52 1 all
#> 20: 52 2 all
#> 21: 52 3 all
#> 22: 52 4 all
#> 23: 52 5 all
#> 24: 52 6 all
#> 25: 26 7 other
#> 26: 26 8 other
#> 27: 26 9 other
#> 28: 26 10 other
#> 29: 26 11 other
#> 30: 26 12 other
#> 31: 26 13 same
#> 32: 26 14 same
#> 33: 26 15 same
#> 34: 26 16 same
#> 35: 26 17 same
#> 36: 26 18 same
#> 37: 26 7 other
#> 38: 26 8 other
#> 39: 26 9 other
#> 40: 26 10 other
#> 41: 26 11 other
#> 42: 26 12 other
#> 43: 26 13 same
#> 44: 26 14 same
#> 45: 26 15 same
#> 46: 26 16 same
#> 47: 26 17 same
#> 48: 26 18 same
#> 49: 26 7 other
#> 50: 26 8 other
#> 51: 26 9 other
#> 52: 26 10 other
#> 53: 26 11 other
#> 54: 26 12 other
#> 55: 26 13 same
#> 56: 26 14 same
#> 57: 26 15 same
#> 58: 26 16 same
#> 59: 26 17 same
#> 60: 26 18 same
#> 61: 26 7 other
#> 62: 26 8 other
#> 63: 26 9 other
#> 64: 26 10 other
#> 65: 26 11 other
#> 66: 26 12 other
#> 67: 26 13 same
#> 68: 26 14 same
#> 69: 26 15 same
#> 70: 26 16 same
#> 71: 26 17 same
#> 72: 26 18 same
#> n.train.groups iteration Train_subsets
#> <int> <int> <fctr>
mlr3resampling::proj_compute(2, pkg.proj.dir)
#> task.i learner.i resampling.i task_id learner_id resampling_id
#> <int> <int> <int> <char> <char> <char>
#> 1: 1 1 1 easy regr.featureless same_other_sizes_cv
#> test.subset train.subsets groups test.fold seed n.train.groups iteration
#> <char> <char> <int> <int> <int> <int> <int>
#> 1: Bob all 52 1 1 52 2
#> Train_subsets start.time end.time process learner pred
#> <char> <POSc> <POSc> <int> <list> <list>
#> 1: all 2026-06-27 03:55:27 2026-06-27 03:55:27 9868 [NULL] [NULL]
#> regr.rmse regr.mae
#> <num> <num>
#> 1: 1.230012 1.009115
6 Combine and save results in a project
Description
proj_results globs the RDS result files in the project
directory, and combines them into a result table via rbindlist().
proj_results_save saves that result table to results.rds
and one or more CSV files (redundant with RDS data, but more
convenient).
proj_fread reads the CSV files, adding columns from
proj_grid.csv to learners*.csv.
Usage
proj_results(proj_dir, verbose=FALSE)
proj_results_save(proj_dir, verbose=FALSE)
proj_fread(proj_dir)Arguments
proj_dir |
Project directory created via
|
verbose |
logical: cat progress? (default FALSE) |
Details
This is Step 3 out of the typical 3 step pipeline (init grid, submit, read results).
Actually, if step 2 worked as intended, then
proj_results_save is called at the end of step 2,
which saves result files to disk that you can read directly:
results.csvcontains test measures for each split.
results.rdscontains additional list columns for
learnerandpred(useful for model interpretation), and can be read viareadRDS()learners.csvonly exists if
learnercolumn is a data frame, in which case it contains the atomic columns, along with meta-data describing each split.learners_*.csvonly exists if
learnercolumn is a named list of data frames: star in file name is expanded using list names, with CSV data taken from atomic columns.
Value
proj_results returns a data table with all columns, whereas
proj_results_save returns the same table with only atomic columns.
proj_fread returns a list
with names corresponding to CSV files in the test directory, and
values are the data tables that result from fread.
Author(s)
Toby Dylan Hocking
Examples
N <- 80
library(data.table)
set.seed(1)
reg.dt <- data.table(
x=runif(N, -2, 2),
noise=runif(N, -2, 2),
person=factor(rep(c("Alice","Bob"), each=0.5*N)))
reg.pattern.list <- list(
easy=function(x, person)x^2,
impossible=function(x, person)(x^2)*(-1)^as.integer(person))
SOAK <- mlr3resampling::ResamplingSameOtherSizesCV$new()
reg.task.list <- list()
for(pattern in names(reg.pattern.list)){
f <- reg.pattern.list[[pattern]]
task.dt <- data.table(reg.dt)[
, y := f(x,person)+rnorm(N, sd=0.5)
][]
task.obj <- mlr3::TaskRegr$new(
pattern, task.dt, target="y")
task.obj$col_roles$feature <- c("x","noise")
task.obj$col_roles$stratum <- "person"
task.obj$col_roles$subset <- "person"
reg.task.list[[pattern]] <- task.obj
}
reg.learner.list <- list(
featureless=mlr3::LearnerRegrFeatureless$new())
if(requireNamespace("rpart")){
reg.learner.list$rpart <- mlr3::LearnerRegrRpart$new()
}
pkg.proj.dir <- tempfile()
mlr3resampling::proj_grid(
pkg.proj.dir,
reg.task.list,
reg.learner.list,
SOAK,
save_learner=function(L){
if(inherits(L, "LearnerRegrRpart")){
list(rpart=L$model$frame)
}
},
order_jobs = function(DT)which(DT$iteration==1)[1:2], # for CRAN.
score_args=mlr3::msrs(c("regr.rmse", "regr.mae")))
#> task.i learner.i resampling.i task_id learner_id resampling_id
#> <int> <int> <int> <char> <char> <char>
#> 1: 1 1 1 easy regr.featureless same_other_sizes_cv
#> 2: 1 2 1 easy regr.rpart same_other_sizes_cv
#> test.subset train.subsets groups test.fold seed n.train.groups iteration
#> <fctr> <char> <int> <int> <int> <int> <int>
#> 1: Alice all 52 1 1 52 1
#> 2: Alice all 52 1 1 52 1
#> Train_subsets
#> <fctr>
#> 1: all
#> 2: all
computed <- mlr3resampling::proj_compute_all(pkg.proj.dir)
result_list <- mlr3resampling::proj_fread(pkg.proj.dir)
result_list$learners_rpart.csv # one row per node in decision tree.
#> grid_job_i var n wt dev yval complexity ncompete
#> <int> <char> <int> <int> <num> <num> <num> <int>
#> 1: 2 x 53 53 65.776216 0.9802453 0.39248606 1
#> 2: 2 x 45 45 33.404555 0.6859744 0.16556010 1
#> 3: 2 x 38 38 15.491474 0.4748379 0.09416380 1
#> 4: 2 x 28 28 7.342024 0.2335667 0.01520725 1
#> 5: 2 <leaf> 19 19 4.244862 0.1034822 0.01000000 0
#> 6: 2 <leaf> 9 9 2.096886 0.5081893 0.01000000 0
#> 7: 2 <leaf> 10 10 1.955711 1.1503975 0.01000000 0
#> 8: 2 <leaf> 7 7 7.023165 1.8321438 0.01000000 0
#> 9: 2 <leaf> 8 8 6.555413 2.6355193 0.01000000 0
#> nsurrogate task_id learner_id resampling_id test.subset train.subsets
#> <int> <char> <char> <char> <char> <char>
#> 1: 0 easy regr.rpart same_other_sizes_cv Alice all
#> 2: 0 easy regr.rpart same_other_sizes_cv Alice all
#> 3: 0 easy regr.rpart same_other_sizes_cv Alice all
#> 4: 1 easy regr.rpart same_other_sizes_cv Alice all
#> 5: 0 easy regr.rpart same_other_sizes_cv Alice all
#> 6: 0 easy regr.rpart same_other_sizes_cv Alice all
#> 7: 0 easy regr.rpart same_other_sizes_cv Alice all
#> 8: 0 easy regr.rpart same_other_sizes_cv Alice all
#> 9: 0 easy regr.rpart same_other_sizes_cv Alice all
#> groups test.fold seed n.train.groups iteration Train_subsets
#> <int> <int> <int> <int> <int> <char>
#> 1: 52 1 1 52 1 all
#> 2: 52 1 1 52 1 all
#> 3: 52 1 1 52 1 all
#> 4: 52 1 1 52 1 all
#> 5: 52 1 1 52 1 all
#> 6: 52 1 1 52 1 all
#> 7: 52 1 1 52 1 all
#> 8: 52 1 1 52 1 all
#> 9: 52 1 1 52 1 all
result_list$results.csv # test error in regr.* columns.
#> grid_job_i task.i learner.i resampling.i task_id learner_id
#> <int> <int> <int> <int> <char> <char>
#> 1: 1 1 1 1 easy regr.featureless
#> 2: 2 1 2 1 easy regr.rpart
#> resampling_id test.subset train.subsets groups test.fold seed
#> <char> <char> <char> <int> <int> <int>
#> 1: same_other_sizes_cv Alice all 52 1 1
#> 2: same_other_sizes_cv Alice all 52 1 1
#> n.train.groups iteration Train_subsets start.time
#> <int> <int> <char> <POSc>
#> 1: 52 1 all 2026-06-27 03:55:28
#> 2: 52 1 all 2026-06-27 03:55:28
#> end.time process regr.rmse regr.mae
#> <POSc> <int> <num> <num>
#> 1: 2026-06-27 03:55:28 9868 1.4218809 1.0945341
#> 2: 2026-06-27 03:55:28 9868 0.8927095 0.6829219
7 Compute several resampling jobs
Description
proj_todo determines which jobs remain to be computed.
proj_compute_all computes all remaining jobs using
future_lapply if available, otherwise
lapply.
proj_compute_mpi computes all remaining jobs in parallel using
MPI (should be run in an R session activated by mpirun or
srun).
proj_submit is a non-blocking call to SLURM sbatch,
asking for a single job with several tasks that run proj_compute_mpi.
Usage
proj_todo(proj_dir)
proj_compute_mpi(proj_dir, verbose=FALSE)
proj_compute_all(proj_dir, verbose=FALSE, LAPPLY)
proj_submit(
proj_dir, tasks = 2, hours = 1, gigabytes = 1,
verbose = FALSE)Arguments
proj_dir |
Project directory created via |
tasks |
Positive integer: |
hours |
Hours of walltime to ask the SLURM scheduler. |
gigabytes |
Gigabytes of memory to ask the SLURM scheduler. |
verbose |
Logical: print messages? |
LAPPLY |
Function like |
Details
This is Step 2 out of the typical 3 step pipeline (init grid, submit, read results).
Value
proj_submit returns the ID of the submitted SLURM job.
proj_compute_all and proj_compute_mpi return a data
table of results computed.
proj_todo returns a vector of job IDs not yet computed.
Author(s)
Toby Dylan Hocking
Examples
N <- 80
library(data.table)
set.seed(1)
reg.dt <- data.table(
x=runif(N, -2, 2),
person=factor(rep(c("Alice","Bob"), each=0.5*N)))
reg.pattern.list <- list(
easy=function(x, person)x^2,
impossible=function(x, person)(x^2)*(-1)^as.integer(person))
SOAK <- mlr3resampling::ResamplingSameOtherSizesCV$new()
reg.task.list <- list()
for(pattern in names(reg.pattern.list)){
f <- reg.pattern.list[[pattern]]
task.dt <- data.table(reg.dt)[
, y := f(x,person)+rnorm(N, sd=0.5)
][]
task.obj <- mlr3::TaskRegr$new(
pattern, task.dt, target="y")
task.obj$col_roles$feature <- "x"
task.obj$col_roles$stratum <- "person"
task.obj$col_roles$subset <- "person"
reg.task.list[[pattern]] <- task.obj
}
reg.learner.list <- list(
featureless=mlr3::LearnerRegrFeatureless$new())
if(requireNamespace("rpart")){
reg.learner.list$rpart <- mlr3::LearnerRegrRpart$new()
}
pkg.proj.dir <- tempfile()
mlr3resampling::proj_grid(
pkg.proj.dir,
reg.task.list,
reg.learner.list,
SOAK,
score_args=mlr3::msrs(c("regr.rmse", "regr.mae")))
#> task.i learner.i resampling.i task_id learner_id
#> <int> <int> <int> <char> <char>
#> 1: 1 1 1 easy regr.featureless
#> 2: 1 1 1 easy regr.featureless
#> 3: 1 1 1 easy regr.featureless
#> 4: 1 1 1 easy regr.featureless
#> 5: 1 1 1 easy regr.featureless
#> 6: 1 1 1 easy regr.featureless
#> 7: 1 2 1 easy regr.rpart
#> 8: 1 2 1 easy regr.rpart
#> 9: 1 2 1 easy regr.rpart
#> 10: 1 2 1 easy regr.rpart
#> 11: 1 2 1 easy regr.rpart
#> 12: 1 2 1 easy regr.rpart
#> 13: 2 1 1 impossible regr.featureless
#> 14: 2 1 1 impossible regr.featureless
#> 15: 2 1 1 impossible regr.featureless
#> 16: 2 1 1 impossible regr.featureless
#> 17: 2 1 1 impossible regr.featureless
#> 18: 2 1 1 impossible regr.featureless
#> 19: 2 2 1 impossible regr.rpart
#> 20: 2 2 1 impossible regr.rpart
#> 21: 2 2 1 impossible regr.rpart
#> 22: 2 2 1 impossible regr.rpart
#> 23: 2 2 1 impossible regr.rpart
#> 24: 2 2 1 impossible regr.rpart
#> 25: 1 1 1 easy regr.featureless
#> 26: 1 1 1 easy regr.featureless
#> 27: 1 1 1 easy regr.featureless
#> 28: 1 1 1 easy regr.featureless
#> 29: 1 1 1 easy regr.featureless
#> 30: 1 1 1 easy regr.featureless
#> 31: 1 1 1 easy regr.featureless
#> 32: 1 1 1 easy regr.featureless
#> 33: 1 1 1 easy regr.featureless
#> 34: 1 1 1 easy regr.featureless
#> 35: 1 1 1 easy regr.featureless
#> 36: 1 1 1 easy regr.featureless
#> 37: 1 2 1 easy regr.rpart
#> 38: 1 2 1 easy regr.rpart
#> 39: 1 2 1 easy regr.rpart
#> 40: 1 2 1 easy regr.rpart
#> 41: 1 2 1 easy regr.rpart
#> 42: 1 2 1 easy regr.rpart
#> 43: 1 2 1 easy regr.rpart
#> 44: 1 2 1 easy regr.rpart
#> 45: 1 2 1 easy regr.rpart
#> 46: 1 2 1 easy regr.rpart
#> 47: 1 2 1 easy regr.rpart
#> 48: 1 2 1 easy regr.rpart
#> 49: 2 1 1 impossible regr.featureless
#> 50: 2 1 1 impossible regr.featureless
#> 51: 2 1 1 impossible regr.featureless
#> 52: 2 1 1 impossible regr.featureless
#> 53: 2 1 1 impossible regr.featureless
#> 54: 2 1 1 impossible regr.featureless
#> 55: 2 1 1 impossible regr.featureless
#> 56: 2 1 1 impossible regr.featureless
#> 57: 2 1 1 impossible regr.featureless
#> 58: 2 1 1 impossible regr.featureless
#> 59: 2 1 1 impossible regr.featureless
#> 60: 2 1 1 impossible regr.featureless
#> 61: 2 2 1 impossible regr.rpart
#> 62: 2 2 1 impossible regr.rpart
#> 63: 2 2 1 impossible regr.rpart
#> 64: 2 2 1 impossible regr.rpart
#> 65: 2 2 1 impossible regr.rpart
#> 66: 2 2 1 impossible regr.rpart
#> 67: 2 2 1 impossible regr.rpart
#> 68: 2 2 1 impossible regr.rpart
#> 69: 2 2 1 impossible regr.rpart
#> 70: 2 2 1 impossible regr.rpart
#> 71: 2 2 1 impossible regr.rpart
#> 72: 2 2 1 impossible regr.rpart
#> task.i learner.i resampling.i task_id learner_id
#> <int> <int> <int> <char> <char>
#> resampling_id test.subset train.subsets groups test.fold seed
#> <char> <fctr> <char> <int> <int> <int>
#> 1: same_other_sizes_cv Alice all 52 1 1
#> 2: same_other_sizes_cv Bob all 52 1 1
#> 3: same_other_sizes_cv Alice all 52 2 1
#> 4: same_other_sizes_cv Bob all 52 2 1
#> 5: same_other_sizes_cv Alice all 52 3 1
#> 6: same_other_sizes_cv Bob all 52 3 1
#> 7: same_other_sizes_cv Alice all 52 1 1
#> 8: same_other_sizes_cv Bob all 52 1 1
#> 9: same_other_sizes_cv Alice all 52 2 1
#> 10: same_other_sizes_cv Bob all 52 2 1
#> 11: same_other_sizes_cv Alice all 52 3 1
#> 12: same_other_sizes_cv Bob all 52 3 1
#> 13: same_other_sizes_cv Alice all 52 1 1
#> 14: same_other_sizes_cv Bob all 52 1 1
#> 15: same_other_sizes_cv Alice all 52 2 1
#> 16: same_other_sizes_cv Bob all 52 2 1
#> 17: same_other_sizes_cv Alice all 52 3 1
#> 18: same_other_sizes_cv Bob all 52 3 1
#> 19: same_other_sizes_cv Alice all 52 1 1
#> 20: same_other_sizes_cv Bob all 52 1 1
#> 21: same_other_sizes_cv Alice all 52 2 1
#> 22: same_other_sizes_cv Bob all 52 2 1
#> 23: same_other_sizes_cv Alice all 52 3 1
#> 24: same_other_sizes_cv Bob all 52 3 1
#> 25: same_other_sizes_cv Alice other 26 1 1
#> 26: same_other_sizes_cv Bob other 26 1 1
#> 27: same_other_sizes_cv Alice other 26 2 1
#> 28: same_other_sizes_cv Bob other 26 2 1
#> 29: same_other_sizes_cv Alice other 26 3 1
#> 30: same_other_sizes_cv Bob other 26 3 1
#> 31: same_other_sizes_cv Alice same 26 1 1
#> 32: same_other_sizes_cv Bob same 26 1 1
#> 33: same_other_sizes_cv Alice same 26 2 1
#> 34: same_other_sizes_cv Bob same 26 2 1
#> 35: same_other_sizes_cv Alice same 26 3 1
#> 36: same_other_sizes_cv Bob same 26 3 1
#> 37: same_other_sizes_cv Alice other 26 1 1
#> 38: same_other_sizes_cv Bob other 26 1 1
#> 39: same_other_sizes_cv Alice other 26 2 1
#> 40: same_other_sizes_cv Bob other 26 2 1
#> 41: same_other_sizes_cv Alice other 26 3 1
#> 42: same_other_sizes_cv Bob other 26 3 1
#> 43: same_other_sizes_cv Alice same 26 1 1
#> 44: same_other_sizes_cv Bob same 26 1 1
#> 45: same_other_sizes_cv Alice same 26 2 1
#> 46: same_other_sizes_cv Bob same 26 2 1
#> 47: same_other_sizes_cv Alice same 26 3 1
#> 48: same_other_sizes_cv Bob same 26 3 1
#> 49: same_other_sizes_cv Alice other 26 1 1
#> 50: same_other_sizes_cv Bob other 26 1 1
#> 51: same_other_sizes_cv Alice other 26 2 1
#> 52: same_other_sizes_cv Bob other 26 2 1
#> 53: same_other_sizes_cv Alice other 26 3 1
#> 54: same_other_sizes_cv Bob other 26 3 1
#> 55: same_other_sizes_cv Alice same 26 1 1
#> 56: same_other_sizes_cv Bob same 26 1 1
#> 57: same_other_sizes_cv Alice same 26 2 1
#> 58: same_other_sizes_cv Bob same 26 2 1
#> 59: same_other_sizes_cv Alice same 26 3 1
#> 60: same_other_sizes_cv Bob same 26 3 1
#> 61: same_other_sizes_cv Alice other 26 1 1
#> 62: same_other_sizes_cv Bob other 26 1 1
#> 63: same_other_sizes_cv Alice other 26 2 1
#> 64: same_other_sizes_cv Bob other 26 2 1
#> 65: same_other_sizes_cv Alice other 26 3 1
#> 66: same_other_sizes_cv Bob other 26 3 1
#> 67: same_other_sizes_cv Alice same 26 1 1
#> 68: same_other_sizes_cv Bob same 26 1 1
#> 69: same_other_sizes_cv Alice same 26 2 1
#> 70: same_other_sizes_cv Bob same 26 2 1
#> 71: same_other_sizes_cv Alice same 26 3 1
#> 72: same_other_sizes_cv Bob same 26 3 1
#> resampling_id test.subset train.subsets groups test.fold seed
#> <char> <fctr> <char> <int> <int> <int>
#> n.train.groups iteration Train_subsets
#> <int> <int> <fctr>
#> 1: 52 1 all
#> 2: 52 2 all
#> 3: 52 3 all
#> 4: 52 4 all
#> 5: 52 5 all
#> 6: 52 6 all
#> 7: 52 1 all
#> 8: 52 2 all
#> 9: 52 3 all
#> 10: 52 4 all
#> 11: 52 5 all
#> 12: 52 6 all
#> 13: 52 1 all
#> 14: 52 2 all
#> 15: 52 3 all
#> 16: 52 4 all
#> 17: 52 5 all
#> 18: 52 6 all
#> 19: 52 1 all
#> 20: 52 2 all
#> 21: 52 3 all
#> 22: 52 4 all
#> 23: 52 5 all
#> 24: 52 6 all
#> 25: 26 7 other
#> 26: 26 8 other
#> 27: 26 9 other
#> 28: 26 10 other
#> 29: 26 11 other
#> 30: 26 12 other
#> 31: 26 13 same
#> 32: 26 14 same
#> 33: 26 15 same
#> 34: 26 16 same
#> 35: 26 17 same
#> 36: 26 18 same
#> 37: 26 7 other
#> 38: 26 8 other
#> 39: 26 9 other
#> 40: 26 10 other
#> 41: 26 11 other
#> 42: 26 12 other
#> 43: 26 13 same
#> 44: 26 14 same
#> 45: 26 15 same
#> 46: 26 16 same
#> 47: 26 17 same
#> 48: 26 18 same
#> 49: 26 7 other
#> 50: 26 8 other
#> 51: 26 9 other
#> 52: 26 10 other
#> 53: 26 11 other
#> 54: 26 12 other
#> 55: 26 13 same
#> 56: 26 14 same
#> 57: 26 15 same
#> 58: 26 16 same
#> 59: 26 17 same
#> 60: 26 18 same
#> 61: 26 7 other
#> 62: 26 8 other
#> 63: 26 9 other
#> 64: 26 10 other
#> 65: 26 11 other
#> 66: 26 12 other
#> 67: 26 13 same
#> 68: 26 14 same
#> 69: 26 15 same
#> 70: 26 16 same
#> 71: 26 17 same
#> 72: 26 18 same
#> n.train.groups iteration Train_subsets
#> <int> <int> <fctr>
if(requireNamespace("future.apply"))future::plan("multisession")
mlr3resampling::proj_compute_all(pkg.proj.dir)
if(requireNamespace("future.apply"))future::plan("sequential")
8 Test a project with smaller data and fewer resampling iterations
Description
Like testJob,
"test" means trying an example with a few small jobs
(default one train/test split per algorithm and data set)
before running the big calculation with all jobs.
Runs proj_grid to create a new project in the
test sub-directory, with a smaller
number of samples in each task, and with only one iteration
per Resampling. Runs proj_compute_all on this new
test project, and then reads any CSV result files.
Usage
proj_test(
proj_dir, min_samples_per_stratum = 10,
edit_learner=edit_learner_default, max_jobs=Inf,
verbose=FALSE, LAPPLY=NULL)Arguments
proj_dir |
Project directory created by |
min_samples_per_stratum |
Minimum number of samples to include in the smallest stratum. Other strata will be down-sampled proportionally. |
edit_learner |
Function which inputs a learner object, and
changes it to take less time for testing. Default calls
|
max_jobs |
Numeric, max number of jobs to test (default Inf). |
verbose |
Logical: print messages? |
LAPPLY |
Function like |
Value
Same value as proj_fread on test project (list of data tables).
Author(s)
Toby Dylan Hocking
Examples
data.table::setDTthreads(1L)
library(data.table)
N <- 8000
set.seed(1)
reg.dt <- data.table(
x=runif(N, -2, 2),
person=factor(rep(c("Alice","Bob"), c(0.1,0.9)*N)))
reg.pattern.list <- list(
easy=function(x, person)x^2,
impossible=function(x, person)(x^2)*(-1)^as.integer(person))
kfold <- mlr3::ResamplingCV$new()
kfold$param_set$values$folds <- 2
reg.task.list <- list()
for(pattern in names(reg.pattern.list)){
f <- reg.pattern.list[[pattern]]
task.dt <- data.table(reg.dt)[
, y := f(x,person)+rnorm(N, sd=0.5)
][]
task.obj <- mlr3::TaskRegr$new(
pattern, task.dt, target="y")
task.obj$col_roles$feature <- "x"
task.obj$col_roles$stratum <- "person"
task.obj$col_roles$subset <- "person"
reg.task.list[[pattern]] <- task.obj
}
reg.learner.list <- list(
featureless=mlr3::LearnerRegrFeatureless$new())
if(requireNamespace("rpart")){
reg.learner.list$rpart <- mlr3::LearnerRegrRpart$new()
}
pkg.proj.dir <- tempfile()
mlr3resampling::proj_grid(
pkg.proj.dir,
reg.task.list,
reg.learner.list,
kfold,
save_learner=function(L){
if(inherits(L, "LearnerRegrRpart")){
list(rpart=L$model$frame)
}
},
score_args=mlr3::msrs(c("regr.rmse", "regr.mae")))
#> task.i learner.i resampling.i task_id learner_id resampling_id
#> <int> <int> <int> <char> <char> <char>
#> 1: 1 1 1 easy regr.featureless cv
#> 2: 1 1 1 easy regr.featureless cv
#> 3: 1 2 1 easy regr.rpart cv
#> 4: 1 2 1 easy regr.rpart cv
#> 5: 2 1 1 impossible regr.featureless cv
#> 6: 2 1 1 impossible regr.featureless cv
#> 7: 2 2 1 impossible regr.rpart cv
#> 8: 2 2 1 impossible regr.rpart cv
#> iteration
#> <int>
#> 1: 1
#> 2: 2
#> 3: 1
#> 4: 2
#> 5: 1
#> 6: 2
#> 7: 1
#> 8: 2
mlr3resampling::proj_test(pkg.proj.dir)
#> $grid_jobs.csv
#> task.i learner.i resampling.i task_id learner_id resampling_id
#> <int> <int> <int> <char> <char> <char>
#> 1: 1 1 1 easy regr.featureless cv
#> 2: 1 2 1 easy regr.rpart cv
#> 3: 2 1 1 impossible regr.featureless cv
#> 4: 2 2 1 impossible regr.rpart cv
#> iteration
#> <int>
#> 1: 1
#> 2: 1
#> 3: 1
#> 4: 1
#>
#> $learners_rpart.csv
#> grid_job_i var n wt dev yval complexity ncompete
#> <int> <char> <int> <int> <num> <num> <num> <int>
#> 1: 2 x 50 50 78.058677 1.3852666 0.390770203 0
#> 2: 2 x 42 42 49.421715 1.0680160 0.390770203 0
#> 3: 2 x 33 33 10.448144 0.5941131 0.023122016 0
#> 4: 2 x 26 26 7.218463 0.4727662 0.018194344 0
#> 5: 2 <leaf> 14 14 2.731358 0.2563854 0.010000000 0
#> 6: 2 <leaf> 12 12 3.066878 0.7252104 0.010000000 0
#> 7: 2 <leaf> 7 7 1.424807 1.0448303 0.010000000 0
#> 8: 2 <leaf> 9 9 4.387637 2.8056601 0.010000000 0
#> 9: 2 <leaf> 8 8 2.216886 3.0508319 0.010000000 0
#> 10: 4 x 50 50 111.331741 1.1434664 0.249241891 0
#> 11: 4 x 39 39 74.483871 0.7478274 0.182219184 0
#> 12: 4 <leaf> 31 31 11.676839 0.3814418 0.005709912 0
#> 13: 4 <leaf> 8 8 42.520253 2.1675716 0.010000000 0
#> 14: 4 <leaf> 11 11 9.099336 2.5461863 0.010000000 0
#> nsurrogate task_id learner_id resampling_id iteration
#> <int> <char> <char> <char> <int>
#> 1: 0 easy regr.rpart cv 1
#> 2: 0 easy regr.rpart cv 1
#> 3: 0 easy regr.rpart cv 1
#> 4: 0 easy regr.rpart cv 1
#> 5: 0 easy regr.rpart cv 1
#> 6: 0 easy regr.rpart cv 1
#> 7: 0 easy regr.rpart cv 1
#> 8: 0 easy regr.rpart cv 1
#> 9: 0 easy regr.rpart cv 1
#> 10: 0 impossible regr.rpart cv 1
#> 11: 0 impossible regr.rpart cv 1
#> 12: 0 impossible regr.rpart cv 1
#> 13: 0 impossible regr.rpart cv 1
#> 14: 0 impossible regr.rpart cv 1
#>
#> $results.csv
#> grid_job_i task.i learner.i resampling.i task_id learner_id
#> <int> <int> <int> <int> <char> <char>
#> 1: 1 1 1 1 easy regr.featureless
#> 2: 2 1 2 1 easy regr.rpart
#> 3: 3 2 1 1 impossible regr.featureless
#> 4: 4 2 2 1 impossible regr.rpart
#> resampling_id iteration start.time end.time process
#> <char> <int> <POSc> <POSc> <int>
#> 1: cv 1 2026-06-27 03:55:29 2026-06-27 03:55:29 9868
#> 2: cv 1 2026-06-27 03:55:29 2026-06-27 03:55:29 9868
#> 3: cv 1 2026-06-27 03:55:29 2026-06-27 03:55:29 9868
#> 4: cv 1 2026-06-27 03:55:29 2026-06-27 03:55:29 9868
#> regr.rmse regr.mae
#> <num> <num>
#> 1: 1.3937502 1.1580176
#> 2: 0.6459229 0.5284654
#> 3: 1.7017688 1.3413757
#> 4: 1.5258893 0.9700115
9 P-values for comparing Same/Other/All training
Description
Same/Other/All K-fold cross-validation (SOAK) results in K measures of test error/accuracy. This function computes P-values (two-sided T-test) between Same and All/Other.
Usage
pvalue(score_in, value.var = NULL, digits=3)Arguments
score_in |
Data table output from |
value.var |
Name of column to use as the evaluation metric in T-test. Default
NULL means to use the first column matching |
digits |
Number of decimal places to show for mean and standard deviation. |
Value
List of class "pvalue" with named elements value.var,
stats, pvalues.
Author(s)
Toby Dylan Hocking
Examples
data.table::setDTthreads(1L)
library(data.table)
set.seed(2)
N <- 150L
x <- runif(N, -3, 3)
sim.dt <- data.table(
x = x,
y = sin(x) + rnorm(N, sd = 0.5),
Subset = rep(c("large", "large", "small"), length.out = N))
sim.task <- mlr3::TaskRegr$new("iid_easy", sim.dt, target = "y")
sim.task$col_roles$feature <- "x"
sim.task$col_roles$subset <- "Subset"
soak <- mlr3resampling::ResamplingSameOtherSizesCV$new()
soak$param_set$values$folds <- 5L
learner_list <- list(
mlr3::lrn("regr.featureless"),
if(requireNamespace("rpart"))mlr3::lrn("regr.rpart"))
bgrid <- mlr3::benchmark_grid(sim.task, learner_list, soak)
result <- mlr3::benchmark(bgrid)
#> INFO [03:55:30.190] [mlr3] Running benchmark with 60 resampling iterations
#> INFO [03:55:30.244] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 1/30)
#> INFO [03:55:30.260] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 2/30)
#> INFO [03:55:30.271] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 3/30)
#> INFO [03:55:30.281] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 4/30)
#> INFO [03:55:30.291] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 5/30)
#> INFO [03:55:30.308] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 6/30)
#> INFO [03:55:30.318] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 7/30)
#> INFO [03:55:30.328] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 8/30)
#> INFO [03:55:30.338] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 9/30)
#> INFO [03:55:30.348] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 10/30)
#> INFO [03:55:30.358] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 11/30)
#> INFO [03:55:30.368] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 12/30)
#> INFO [03:55:30.378] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 13/30)
#> INFO [03:55:30.389] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 14/30)
#> INFO [03:55:30.399] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 15/30)
#> INFO [03:55:30.409] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 16/30)
#> INFO [03:55:30.420] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 17/30)
#> INFO [03:55:30.430] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 18/30)
#> INFO [03:55:30.441] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 19/30)
#> INFO [03:55:30.451] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 20/30)
#> INFO [03:55:30.462] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 21/30)
#> INFO [03:55:30.473] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 22/30)
#> INFO [03:55:30.484] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 23/30)
#> INFO [03:55:30.495] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 24/30)
#> INFO [03:55:30.511] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 25/30)
#> INFO [03:55:30.522] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 26/30)
#> INFO [03:55:30.532] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 27/30)
#> INFO [03:55:30.542] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 28/30)
#> INFO [03:55:30.552] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 29/30)
#> INFO [03:55:30.562] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 30/30)
#> INFO [03:55:30.573] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 1/30)
#> INFO [03:55:30.586] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 2/30)
#> INFO [03:55:30.599] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 3/30)
#> INFO [03:55:30.612] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 4/30)
#> INFO [03:55:30.625] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 5/30)
#> INFO [03:55:30.638] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 6/30)
#> INFO [03:55:30.651] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 7/30)
#> INFO [03:55:30.664] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 8/30)
#> INFO [03:55:30.676] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 9/30)
#> INFO [03:55:30.689] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 10/30)
#> INFO [03:55:30.702] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 11/30)
#> INFO [03:55:30.720] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 12/30)
#> INFO [03:55:30.732] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 13/30)
#> INFO [03:55:30.745] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 14/30)
#> INFO [03:55:30.758] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 15/30)
#> INFO [03:55:30.770] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 16/30)
#> INFO [03:55:30.783] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 17/30)
#> INFO [03:55:30.796] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 18/30)
#> INFO [03:55:30.809] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 19/30)
#> INFO [03:55:30.822] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 20/30)
#> INFO [03:55:30.836] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 21/30)
#> INFO [03:55:30.849] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 22/30)
#> INFO [03:55:30.863] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 23/30)
#> INFO [03:55:30.877] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 24/30)
#> INFO [03:55:30.890] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 25/30)
#> INFO [03:55:30.903] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 26/30)
#> INFO [03:55:30.916] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 27/30)
#> INFO [03:55:30.934] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 28/30)
#> INFO [03:55:30.948] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 29/30)
#> INFO [03:55:30.962] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 30/30)
#> INFO [03:55:30.987] [mlr3] Finished benchmark
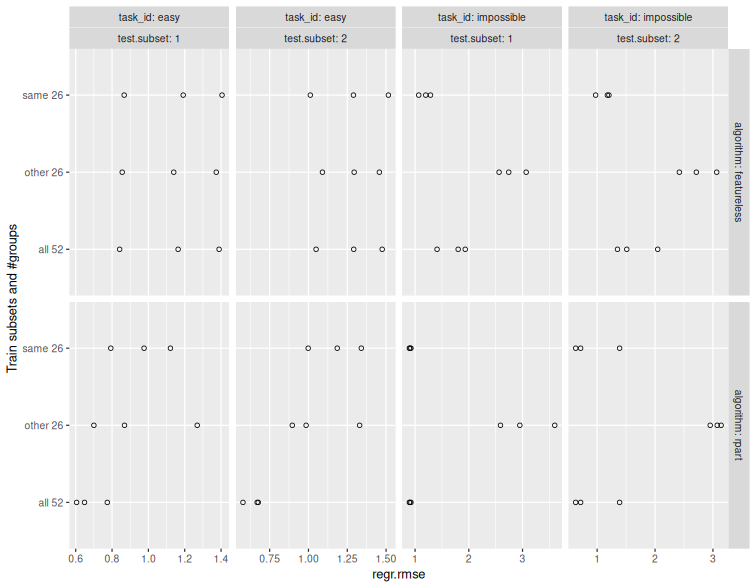
score.dt <- mlr3resampling::score(result, mlr3::msr("regr.rmse"))
if(requireNamespace("ggplot2")) plot(score.dt)
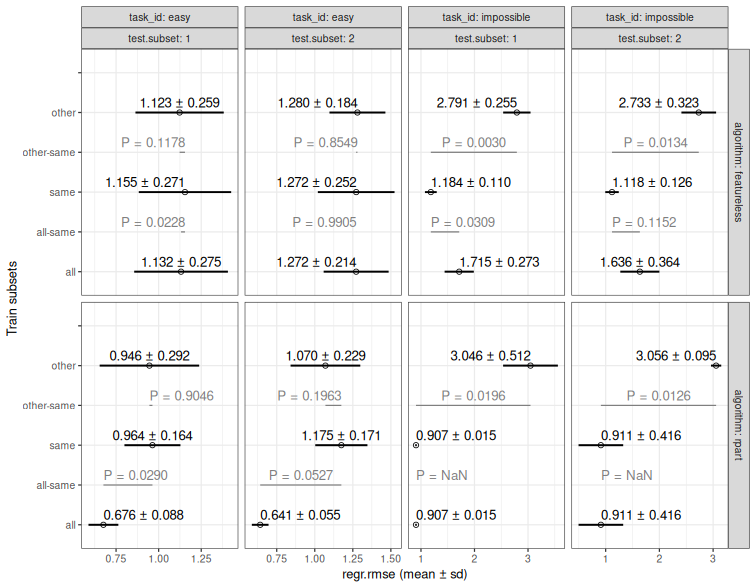
p.list <- mlr3resampling::pvalue(score.dt)
if(requireNamespace("ggplot2")) plot(p.list)
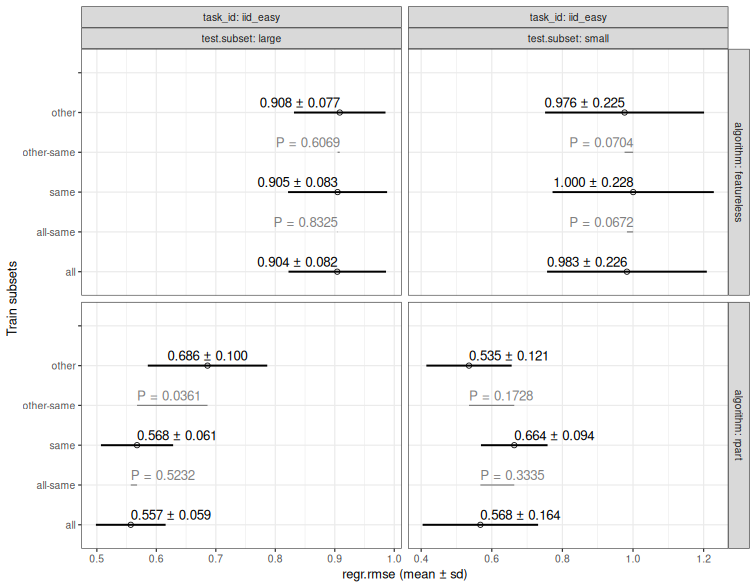
10 P-values for full versus down-sampled SOAK results
Description
For one test.subset, compute summary statistics and paired
two-sided t-test P-values that compare same versus
all/other, for two train-size panels:
full (n.train.groups == groups) and down-sampled
(n.train.groups == min(groups)).
Usage
pvalue_downsample(
score_in,
value.var = NULL,
digits = 3
)Arguments
score_in |
Data table output from |
value.var |
Name of column to use as the evaluation metric in T-test. Default
NULL means to use the first column matching |
digits |
Non-negative integer number of digits to print in mean/SD text labels. |
Value
List of class "pvalue_downsample" with named elements
subset_name, model_name, value.var,
stats, and pvalues. subset_name and
model_name are inferred from score_in.
Author(s)
Daniel Agyapong
Examples
data.table::setDTthreads(1L)
library(data.table)
set.seed(2)
N <- 150L
x <- runif(N, -3, 3)
sim.dt <- data.table(
x = x,
y = sin(x) + rnorm(N, sd = 0.5),
Subset = rep(c("large", "large", "small"), length.out = N))
sim.task <- mlr3::TaskRegr$new("iid_easy", sim.dt, target = "y")
sim.task$col_roles$feature <- "x"
sim.task$col_roles$subset <- "Subset"
soak <- mlr3resampling::ResamplingSameOtherSizesCV$new()
soak$param_set$values$folds <- 5L
soak$param_set$values$sizes <- 0L
learner_list <- list(
mlr3::lrn("regr.featureless"),
if(requireNamespace("rpart"))mlr3::lrn("regr.rpart"))
bgrid <- mlr3::benchmark_grid(sim.task, learner_list, soak)
result <- mlr3::benchmark(bgrid)
#> INFO [03:55:32.661] [mlr3] Running benchmark with 100 resampling iterations
#> INFO [03:55:32.740] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 1/50)
#> INFO [03:55:32.753] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 2/50)
#> INFO [03:55:32.765] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 3/50)
#> INFO [03:55:32.776] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 4/50)
#> INFO [03:55:32.787] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 5/50)
#> INFO [03:55:32.799] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 6/50)
#> INFO [03:55:32.810] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 7/50)
#> INFO [03:55:32.821] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 8/50)
#> INFO [03:55:32.832] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 9/50)
#> INFO [03:55:32.843] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 10/50)
#> INFO [03:55:32.854] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 11/50)
#> INFO [03:55:32.865] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 12/50)
#> INFO [03:55:32.884] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 13/50)
#> INFO [03:55:32.897] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 14/50)
#> INFO [03:55:32.907] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 15/50)
#> INFO [03:55:32.918] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 16/50)
#> INFO [03:55:32.928] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 17/50)
#> INFO [03:55:32.938] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 18/50)
#> INFO [03:55:32.949] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 19/50)
#> INFO [03:55:32.959] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 20/50)
#> INFO [03:55:32.970] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 21/50)
#> INFO [03:55:32.980] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 22/50)
#> INFO [03:55:32.990] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 23/50)
#> INFO [03:55:33.001] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 24/50)
#> INFO [03:55:33.018] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 25/50)
#> INFO [03:55:33.031] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 26/50)
#> INFO [03:55:33.042] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 27/50)
#> INFO [03:55:33.052] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 28/50)
#> INFO [03:55:33.063] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 29/50)
#> INFO [03:55:33.075] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 30/50)
#> INFO [03:55:33.086] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 31/50)
#> INFO [03:55:33.097] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 32/50)
#> INFO [03:55:33.108] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 33/50)
#> INFO [03:55:33.119] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 34/50)
#> INFO [03:55:33.130] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 35/50)
#> INFO [03:55:33.141] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 36/50)
#> INFO [03:55:33.152] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 37/50)
#> INFO [03:55:33.171] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 38/50)
#> INFO [03:55:33.183] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 39/50)
#> INFO [03:55:33.194] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 40/50)
#> INFO [03:55:33.205] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 41/50)
#> INFO [03:55:33.215] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 42/50)
#> INFO [03:55:33.226] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 43/50)
#> INFO [03:55:33.237] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 44/50)
#> INFO [03:55:33.248] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 45/50)
#> INFO [03:55:33.259] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 46/50)
#> INFO [03:55:33.270] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 47/50)
#> INFO [03:55:33.281] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 48/50)
#> INFO [03:55:33.293] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 49/50)
#> INFO [03:55:33.311] [mlr3] Applying learner 'regr.featureless' on task 'iid_easy' (iter 50/50)
#> INFO [03:55:33.323] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 1/50)
#> INFO [03:55:33.337] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 2/50)
#> INFO [03:55:33.350] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 3/50)
#> INFO [03:55:33.364] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 4/50)
#> INFO [03:55:33.376] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 5/50)
#> INFO [03:55:33.390] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 6/50)
#> INFO [03:55:33.403] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 7/50)
#> INFO [03:55:33.416] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 8/50)
#> INFO [03:55:33.431] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 9/50)
#> INFO [03:55:33.453] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 10/50)
#> INFO [03:55:33.468] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 11/50)
#> INFO [03:55:33.482] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 12/50)
#> INFO [03:55:33.494] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 13/50)
#> INFO [03:55:33.507] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 14/50)
#> INFO [03:55:33.520] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 15/50)
#> INFO [03:55:33.534] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 16/50)
#> INFO [03:55:33.547] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 17/50)
#> INFO [03:55:33.561] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 18/50)
#> INFO [03:55:33.580] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 19/50)
#> INFO [03:55:33.597] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 20/50)
#> INFO [03:55:33.611] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 21/50)
#> INFO [03:55:33.624] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 22/50)
#> INFO [03:55:33.637] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 23/50)
#> INFO [03:55:33.650] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 24/50)
#> INFO [03:55:33.663] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 25/50)
#> INFO [03:55:33.676] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 26/50)
#> INFO [03:55:33.690] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 27/50)
#> INFO [03:55:33.703] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 28/50)
#> INFO [03:55:33.723] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 29/50)
#> INFO [03:55:33.738] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 30/50)
#> INFO [03:55:33.752] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 31/50)
#> INFO [03:55:33.765] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 32/50)
#> INFO [03:55:33.778] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 33/50)
#> INFO [03:55:33.791] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 34/50)
#> INFO [03:55:33.805] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 35/50)
#> INFO [03:55:33.818] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 36/50)
#> INFO [03:55:33.831] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 37/50)
#> INFO [03:55:33.845] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 38/50)
#> INFO [03:55:33.866] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 39/50)
#> INFO [03:55:33.882] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 40/50)
#> INFO [03:55:33.895] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 41/50)
#> INFO [03:55:33.908] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 42/50)
#> INFO [03:55:33.921] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 43/50)
#> INFO [03:55:33.934] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 44/50)
#> INFO [03:55:33.947] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 45/50)
#> INFO [03:55:33.960] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 46/50)
#> INFO [03:55:33.974] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 47/50)
#> INFO [03:55:33.994] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 48/50)
#> INFO [03:55:34.011] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 49/50)
#> INFO [03:55:34.024] [mlr3] Applying learner 'regr.rpart' on task 'iid_easy' (iter 50/50)
#> INFO [03:55:34.058] [mlr3] Finished benchmark
score.dt <- mlr3resampling::score(result, mlr3::msr("regr.rmse"))
if(requireNamespace("ggplot2")) plot(score.dt)
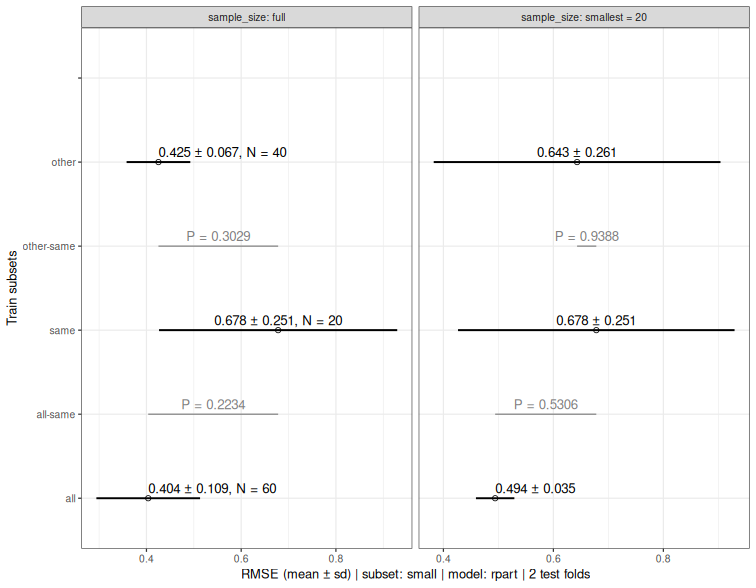
down.list <- mlr3resampling::pvalue_downsample(score.dt[
task_id == "iid_easy" & test.subset == "large" & algorithm == "rpart"])
if(requireNamespace("ggplot2")) plot(down.list)
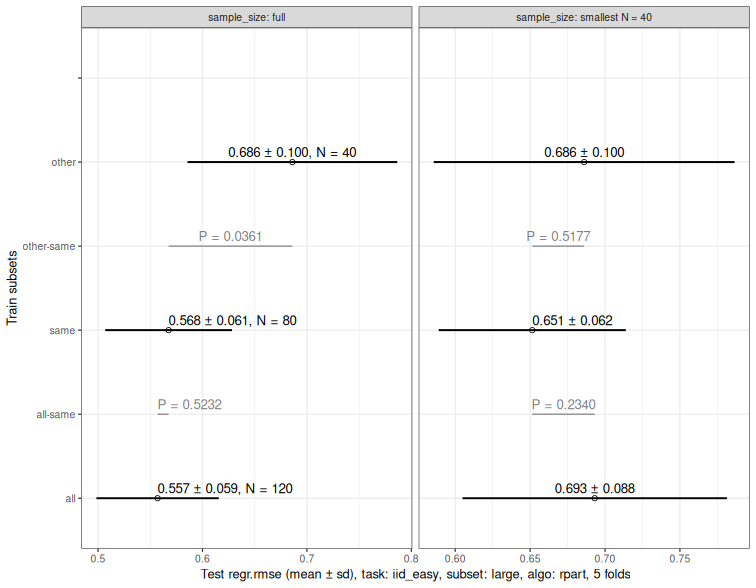
11 Score benchmark results
Description
Computes a data table of scores.
Usage
score(bench.result, ...)Arguments
bench.result |
Output of |
... |
Additional arguments to pass to |
Value
data table with scores.
Author(s)
Toby Dylan Hocking
Examples
N <- 80
library(data.table)
set.seed(1)
reg.dt <- data.table(
x=runif(N, -2, 2),
person=rep(1:2, each=0.5*N))
reg.pattern.list <- list(
easy=function(x, person)x^2,
impossible=function(x, person)(x^2)*(-1)^person)
SOAK <- mlr3resampling::ResamplingSameOtherSizesCV$new()
reg.task.list <- list()
for(pattern in names(reg.pattern.list)){
f <- reg.pattern.list[[pattern]]
yname <- paste0("y_",pattern)
reg.dt[, (yname) := f(x,person)+rnorm(N, sd=0.5)][]
task.dt <- reg.dt[, c("x","person",yname), with=FALSE]
task.obj <- mlr3::TaskRegr$new(
pattern, task.dt, target=yname)
task.obj$col_roles$stratum <- "person"
task.obj$col_roles$subset <- "person"
reg.task.list[[pattern]] <- task.obj
}
reg.learner.list <- list(
mlr3::LearnerRegrFeatureless$new())
if(requireNamespace("rpart")){
reg.learner.list$rpart <- mlr3::LearnerRegrRpart$new()
}
(bench.grid <- mlr3::benchmark_grid(
reg.task.list,
reg.learner.list,
SOAK))
#> task learner resampling
#> <char> <char> <char>
#> 1: easy regr.featureless same_other_sizes_cv
#> 2: easy regr.rpart same_other_sizes_cv
#> 3: impossible regr.featureless same_other_sizes_cv
#> 4: impossible regr.rpart same_other_sizes_cv
bench.result <- mlr3::benchmark(bench.grid)
#> INFO [03:55:35.384] [mlr3] Running benchmark with 72 resampling iterations
#> INFO [03:55:35.392] [mlr3] Applying learner 'regr.featureless' on task 'easy' (iter 1/18)
#> INFO [03:55:35.404] [mlr3] Applying learner 'regr.featureless' on task 'easy' (iter 2/18)
#> INFO [03:55:35.439] [mlr3] Applying learner 'regr.featureless' on task 'easy' (iter 3/18)
#> INFO [03:55:35.452] [mlr3] Applying learner 'regr.featureless' on task 'easy' (iter 4/18)
#> INFO [03:55:35.463] [mlr3] Applying learner 'regr.featureless' on task 'easy' (iter 5/18)
#> INFO [03:55:35.474] [mlr3] Applying learner 'regr.featureless' on task 'easy' (iter 6/18)
#> INFO [03:55:35.485] [mlr3] Applying learner 'regr.featureless' on task 'easy' (iter 7/18)
#> INFO [03:55:35.496] [mlr3] Applying learner 'regr.featureless' on task 'easy' (iter 8/18)
#> INFO [03:55:35.506] [mlr3] Applying learner 'regr.featureless' on task 'easy' (iter 9/18)
#> INFO [03:55:35.517] [mlr3] Applying learner 'regr.featureless' on task 'easy' (iter 10/18)
#> INFO [03:55:35.527] [mlr3] Applying learner 'regr.featureless' on task 'easy' (iter 11/18)
#> INFO [03:55:35.538] [mlr3] Applying learner 'regr.featureless' on task 'easy' (iter 12/18)
#> INFO [03:55:35.549] [mlr3] Applying learner 'regr.featureless' on task 'easy' (iter 13/18)
#> INFO [03:55:35.567] [mlr3] Applying learner 'regr.featureless' on task 'easy' (iter 14/18)
#> INFO [03:55:35.581] [mlr3] Applying learner 'regr.featureless' on task 'easy' (iter 15/18)
#> INFO [03:55:35.593] [mlr3] Applying learner 'regr.featureless' on task 'easy' (iter 16/18)
#> INFO [03:55:35.604] [mlr3] Applying learner 'regr.featureless' on task 'easy' (iter 17/18)
#> INFO [03:55:35.614] [mlr3] Applying learner 'regr.featureless' on task 'easy' (iter 18/18)
#> INFO [03:55:35.625] [mlr3] Applying learner 'regr.rpart' on task 'easy' (iter 1/18)
#> INFO [03:55:35.638] [mlr3] Applying learner 'regr.rpart' on task 'easy' (iter 2/18)
#> INFO [03:55:35.652] [mlr3] Applying learner 'regr.rpart' on task 'easy' (iter 3/18)
#> INFO [03:55:35.666] [mlr3] Applying learner 'regr.rpart' on task 'easy' (iter 4/18)
#> INFO [03:55:35.679] [mlr3] Applying learner 'regr.rpart' on task 'easy' (iter 5/18)
#> INFO [03:55:35.700] [mlr3] Applying learner 'regr.rpart' on task 'easy' (iter 6/18)
#> INFO [03:55:35.716] [mlr3] Applying learner 'regr.rpart' on task 'easy' (iter 7/18)
#> INFO [03:55:35.731] [mlr3] Applying learner 'regr.rpart' on task 'easy' (iter 8/18)
#> INFO [03:55:35.745] [mlr3] Applying learner 'regr.rpart' on task 'easy' (iter 9/18)
#> INFO [03:55:35.758] [mlr3] Applying learner 'regr.rpart' on task 'easy' (iter 10/18)
#> INFO [03:55:35.772] [mlr3] Applying learner 'regr.rpart' on task 'easy' (iter 11/18)
#> INFO [03:55:35.785] [mlr3] Applying learner 'regr.rpart' on task 'easy' (iter 12/18)
#> INFO [03:55:35.799] [mlr3] Applying learner 'regr.rpart' on task 'easy' (iter 13/18)
#> INFO [03:55:35.814] [mlr3] Applying learner 'regr.rpart' on task 'easy' (iter 14/18)
#> INFO [03:55:35.835] [mlr3] Applying learner 'regr.rpart' on task 'easy' (iter 15/18)
#> INFO [03:55:35.851] [mlr3] Applying learner 'regr.rpart' on task 'easy' (iter 16/18)
#> INFO [03:55:35.865] [mlr3] Applying learner 'regr.rpart' on task 'easy' (iter 17/18)
#> INFO [03:55:35.880] [mlr3] Applying learner 'regr.rpart' on task 'easy' (iter 18/18)
#> INFO [03:55:35.894] [mlr3] Applying learner 'regr.featureless' on task 'impossible' (iter 1/18)
#> INFO [03:55:35.905] [mlr3] Applying learner 'regr.featureless' on task 'impossible' (iter 2/18)
#> INFO [03:55:35.915] [mlr3] Applying learner 'regr.featureless' on task 'impossible' (iter 3/18)
#> INFO [03:55:35.926] [mlr3] Applying learner 'regr.featureless' on task 'impossible' (iter 4/18)
#> INFO [03:55:35.937] [mlr3] Applying learner 'regr.featureless' on task 'impossible' (iter 5/18)
#> INFO [03:55:35.947] [mlr3] Applying learner 'regr.featureless' on task 'impossible' (iter 6/18)
#> INFO [03:55:35.966] [mlr3] Applying learner 'regr.featureless' on task 'impossible' (iter 7/18)
#> INFO [03:55:35.979] [mlr3] Applying learner 'regr.featureless' on task 'impossible' (iter 8/18)
#> INFO [03:55:35.991] [mlr3] Applying learner 'regr.featureless' on task 'impossible' (iter 9/18)
#> INFO [03:55:36.003] [mlr3] Applying learner 'regr.featureless' on task 'impossible' (iter 10/18)
#> INFO [03:55:36.013] [mlr3] Applying learner 'regr.featureless' on task 'impossible' (iter 11/18)
#> INFO [03:55:36.023] [mlr3] Applying learner 'regr.featureless' on task 'impossible' (iter 12/18)
#> INFO [03:55:36.034] [mlr3] Applying learner 'regr.featureless' on task 'impossible' (iter 13/18)
#> INFO [03:55:36.044] [mlr3] Applying learner 'regr.featureless' on task 'impossible' (iter 14/18)
#> INFO [03:55:36.055] [mlr3] Applying learner 'regr.featureless' on task 'impossible' (iter 15/18)
#> INFO [03:55:36.066] [mlr3] Applying learner 'regr.featureless' on task 'impossible' (iter 16/18)
#> INFO [03:55:36.077] [mlr3] Applying learner 'regr.featureless' on task 'impossible' (iter 17/18)
#> INFO [03:55:36.095] [mlr3] Applying learner 'regr.featureless' on task 'impossible' (iter 18/18)
#> INFO [03:55:36.109] [mlr3] Applying learner 'regr.rpart' on task 'impossible' (iter 1/18)
#> INFO [03:55:36.124] [mlr3] Applying learner 'regr.rpart' on task 'impossible' (iter 2/18)
#> INFO [03:55:36.139] [mlr3] Applying learner 'regr.rpart' on task 'impossible' (iter 3/18)
#> INFO [03:55:36.153] [mlr3] Applying learner 'regr.rpart' on task 'impossible' (iter 4/18)
#> INFO [03:55:36.168] [mlr3] Applying learner 'regr.rpart' on task 'impossible' (iter 5/18)
#> INFO [03:55:36.182] [mlr3] Applying learner 'regr.rpart' on task 'impossible' (iter 6/18)
#> INFO [03:55:36.197] [mlr3] Applying learner 'regr.rpart' on task 'impossible' (iter 7/18)
#> INFO [03:55:36.211] [mlr3] Applying learner 'regr.rpart' on task 'impossible' (iter 8/18)
#> INFO [03:55:36.233] [mlr3] Applying learner 'regr.rpart' on task 'impossible' (iter 9/18)
#> INFO [03:55:36.250] [mlr3] Applying learner 'regr.rpart' on task 'impossible' (iter 10/18)
#> INFO [03:55:36.265] [mlr3] Applying learner 'regr.rpart' on task 'impossible' (iter 11/18)
#> INFO [03:55:36.278] [mlr3] Applying learner 'regr.rpart' on task 'impossible' (iter 12/18)
#> INFO [03:55:36.292] [mlr3] Applying learner 'regr.rpart' on task 'impossible' (iter 13/18)
#> INFO [03:55:36.305] [mlr3] Applying learner 'regr.rpart' on task 'impossible' (iter 14/18)
#> INFO [03:55:36.319] [mlr3] Applying learner 'regr.rpart' on task 'impossible' (iter 15/18)
#> INFO [03:55:36.333] [mlr3] Applying learner 'regr.rpart' on task 'impossible' (iter 16/18)
#> INFO [03:55:36.347] [mlr3] Applying learner 'regr.rpart' on task 'impossible' (iter 17/18)
#> INFO [03:55:36.369] [mlr3] Applying learner 'regr.rpart' on task 'impossible' (iter 18/18)
#> INFO [03:55:36.399] [mlr3] Finished benchmark
bench.score <- mlr3resampling::score(bench.result, mlr3::msr("regr.rmse"))
plot(bench.score)